Data Assimilation
What is Data Assimilation ?
Data Assimilation is an approach / method for combining high-fidelity observations with low-fidelity model output to improve the latter.
We want to predict the state of the system and its future in the best possible way.
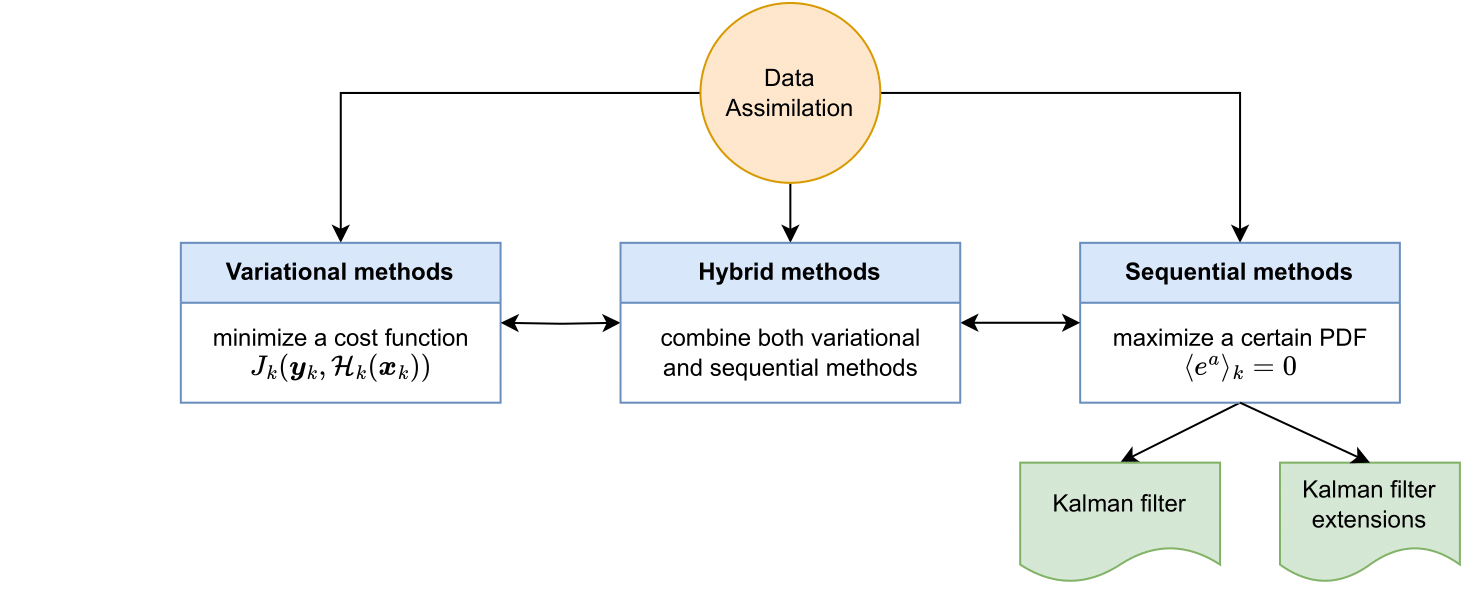
Data assimilation available methods.
Sequential Data Assimilation : Kalman Filter
Initialization: initial estimate for \(\mathbf{x}^a_0\).
At every \(k\) Data Assimilation cycle,
Prediction / Forecast step: the forecast state \(\mathbf{x}_k^f\) is given by the foreward model \(\mathcal{M}_{k-1:k}\) of our system.
Correction / analysis step: we perform a correction of the state \(\mathbf{x}_k^a\) based on the forecast state \(\mathbf{x}_k^f\) and some high-fidelity observation \(\mathbf{y}_k\) through the estimation of the so-called Kalman gain matrix \(\mathbf{K}_k\) that minimizes the error covariance matrix of the updated state \(\mathbf{P}_k^a\).
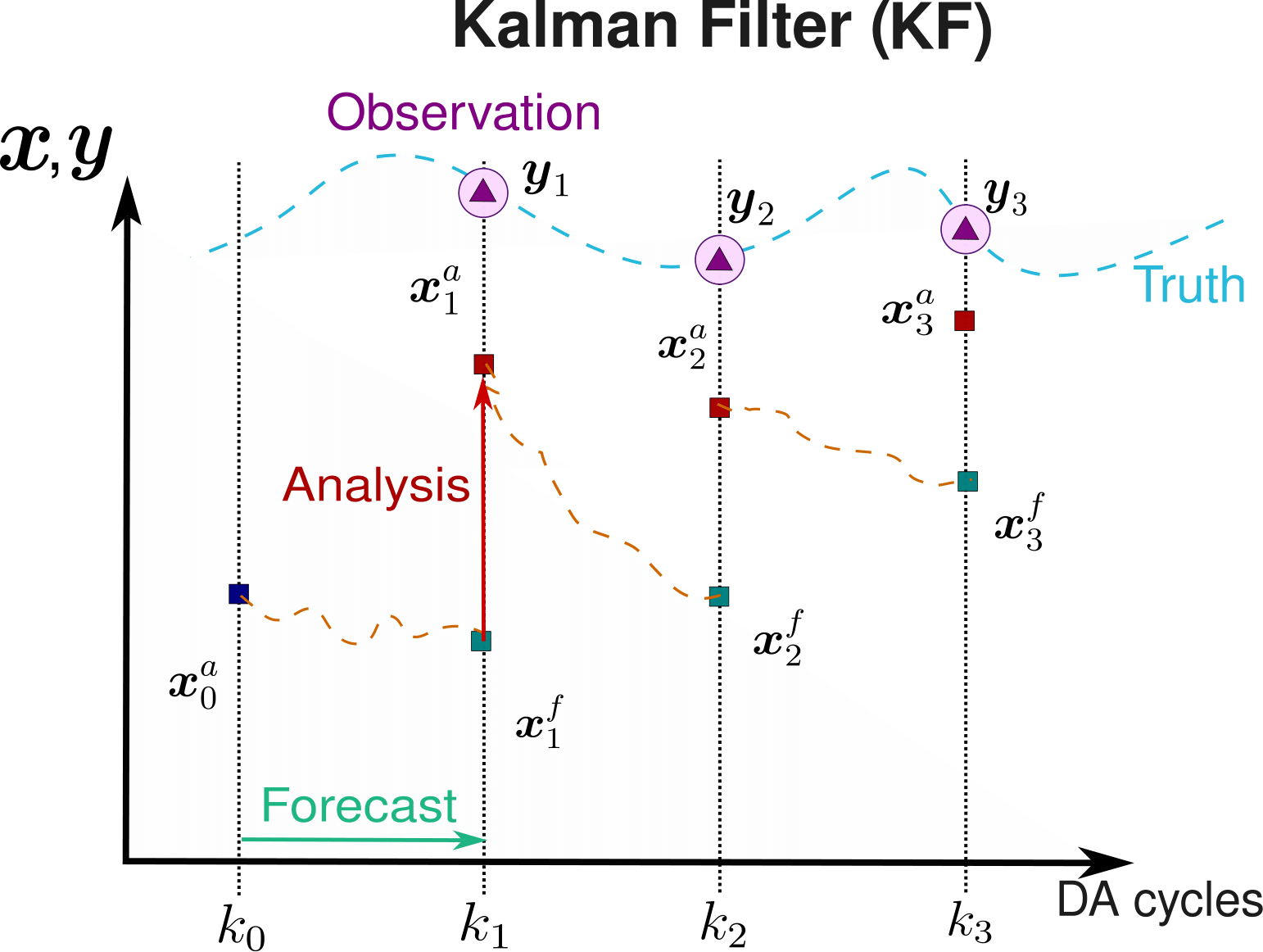
Kalman Filter algorithm scheme.
The inconveniences of the Kalman Filter are:
The Kalman Filter - also the Extended Kalman Filter (EKF) - only works for moderate deviations from linearity and Gaussianity:
High dimensionality of the error covariance matrix \(\mathbf{P}_k\), with a number of degree of freedom equal to \(n_{\textrm{vars}} \times n_{\textrm{cells}}\):
The possible alternatives to the KF are:
Particle filter: cannot yet to be applied to very high dimensional systems (\(m\) = size the ensemble).
Ensemble Kalman Filter:
High dimensional systems \(\rightarrow\) we avoid the explicit defintion of \(\mathbf{P}_k\).
Non-linear models \(\rightarrow\) Monte-Carlo realisations.
But underestimation of \(\mathbf{P}_k^a\) \(\rightarrow\) inflation and localisation.
Ensemble Kalman Filter with extended state
The system state \(\mathbf{x}_k\) is as follows:
where:
\(\mathbf{u}_k\) is the state matrix (can contain velocities, pressure, temperature…) of the domain at the time instant \(k\).
\(\theta_k\) are the coefficients from the model we want to infer at the time instant \(k\).
The observation data \(\mathbf{y}_k\) is defined as
Observation data may be built using:
Velocity, pressure, temperature and more… values.
Instantaneous global force coefficients \(C_D\), \(C_L\), \(C_f\), …
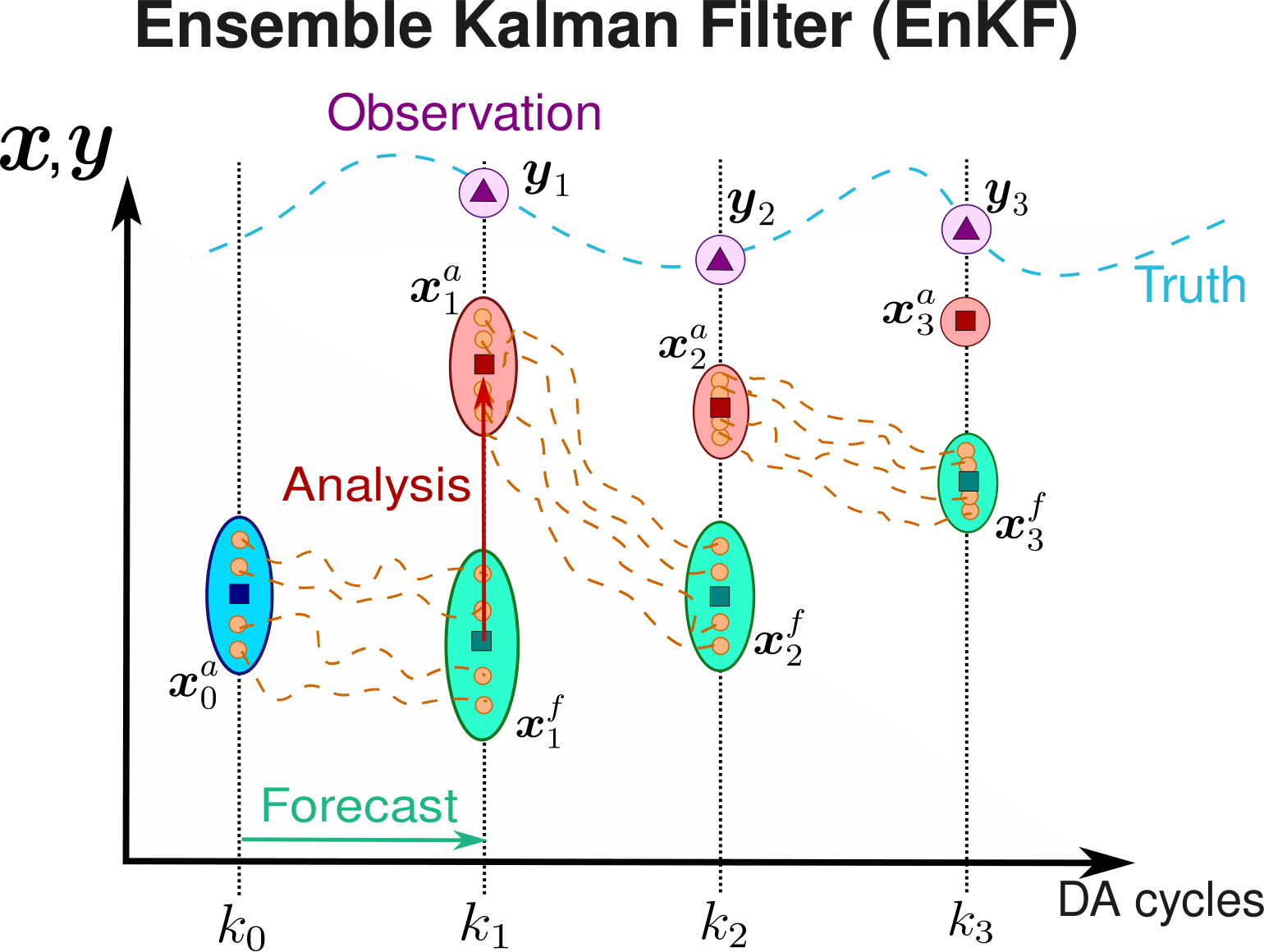
Ensemble Kalman Filter algorithm scheme.
The following matrices are needed to build the EnKF algorithm:
Observation covariance matrix \(\mathbf{R}_k\): we assume Gaussian, non-correlated incertainty for the observations (\(\sigma_{i,k}\) is the standard deviation for the variable \(i\) at time instant \(k\)).
Sampling matrix \(\mathcal{H} \left( \mathbf{x}^f_i \right)\): it is the projection the model into the position of the observations.
Anomaly matrices for the system’s state \(\mathbf{x}^f_k\) and sampling \(\mathcal{H} \left( \mathbf{x}^f_i \right) = \mathbf{s}^f_k\) matrices. They measure the deviation of each realisations with respect to the mean.
Kalman Gain matrix:
Multigrid Ensemble Kalman Filter (MGEnKF)
MultiFidelity Ensemble Kalman Filter (MFEnKF)
The MFEnKF is built using 3 sources of information:
The principal members, denoted as \(X_i\)
The control members, denoted as \(\hat{U}_i\)
The ancillary members, denoted as \(U_i\)
Control members \(\hat{U}_i\) are a projection of the principal members \(X_i\) using the projection operator \(\mathbf{\Phi}_r^\star\):
The MFEnKF methodology is sketched below, from [popov_multifidelity_2021]:

The Kalman gain \(\tilde{K}_i\) is computed using the 3 ensemble types.
Ensemble means
Ensemble anomaly matrices
Ensemble covariances
Kalman gain intermediate covariances
Computing Kalman Gain
Update and total variate
Each variable can be updated:
The total variate Z represents the combined prior and posterior knowledge through the linear control variate technique:
where S = |Phi_r| / 2